6.4_빅데이터기술
HIA(Hybrid Information Architecture)
출처 : https://blog.lgcns.com/1107
HIA(Hybrid Information Architecture)의 개념
전사 관점의 빅데이터 시스템을 구축하기 위해서는 기존의 정보계와 빅데이터 환경을 수용할 수 있는 환경과 균형과 조화가 필수적인데, 이런 환경을 지원해주는 아키텍처가 HIA(Hybrid Information Architecture)입니다.
2014년 Gartner에서는 Logical DW(Data Warehouse)라는 아키텍처를 제시하며 HIA로 DW 인프라가 확대될 것으로 예측하고 관련 시장도 지속 성장할 것으로 예측하였습니다.

l 출처: Gartner Logical Data Warehouse
Oracle에서는 BDA(Big Data Appliance), Microsoft에서는 Analytic Platform System, Teradata에서는 Unified Data Warehouse 등의 아키텍처를 제시하며 HIA를 지원하고 있습니다. 일부 금융권에서는 HIA 기반의 시스템을 구축 중이거나 구체적인 구축 계획을 수립 중입니다.

l 출처: Oracle

l 출처: Microsoft
국내 금융권의 빅데이터 트렌드를 살펴보겠습니다.
CRM(Customer Relationship Management) 측면에서 VOC(Voice Of Customer) 분석 시스템 구축하거나 머신 러닝을 통한 고객 거래 데이터를 분석하여 세분화된 추천 시스템을 구축하고, 은행의 수신•여신 규모에 따라 고객을 세분화하여 적합한 금융 상품을 추천하고 있으며, 각종 로그 데이터를 분석하여 사내의 통합 보안 시스템을 구축하고 있습니다.
보험에서는 기존의 FDS(Fraud Detection System) 시스템을 머신 러닝과 통계적 기법을 적용하여 개선하는 사업 등이 추진되고 있습니다. 인프라 측면에서 Hadoop 플랫폼을 도입하여 기존에 축적되지 않던 비정형 데이터들을 미래 활용을 위해 축적하는 사업도 진행하고 있습니다.
현 단계에서는 기존 DW•BI 환경에서 HIA 환경으로 넘어가는 과도기적인 단계로 기존 정보계에 대한 의존도가 높으며, Hadoop 환경에 대해서는 검증 단계이거나 Pilot 형태로 적용하여 기능, 성능, 보안 등을 확인합니다.
HIA 구성도와 상세 설명
DW Platform과 Hadoop Platform을 통합한 HIA는 Data Source, Data Collect, Data Store, Data Analysis로 구성됩니다.

실선 화살표: Batch Data Flow, 점선 화살표: Interactive Data Flow
1) Large Data: Structured Big Data. 기존의 DW DBMS에 저장하기 어려운 대량의 데이터. 예) 통신의 CDR(Call Data Record), 제조업 라인의 Machine-Generating 데이터, IoT 센서 데이터 등
실선으로 표시되는 데이터 흐름은 주로 야간 배치를 이용하여 대량의 데이터를 전송•적재하는 것을 의미하며, 점선은 Data Store에 저장된 데이터를 조회하거나 참조하는 데이터 흐름입니다.
A, B, C, D, E의 의미는 아래와 같습니다.
A. ETL 도구, Sqoop, Flume을 이용한 데이터 수집
B. DW Platform과 Hadoop Platform간 데이터 인터페이스
C. DW Platform 데이터를 Hadoop Platform으로 아카이빙
D. 데이터 가상화. 이기종 혹은 분산된 다양한 DB의 데이터를 물리적 통합 없이
하나의 DB 처럼 활용하는 기법
E. OLAP, 데이터 시각화, 리포팅 툴을 활용한 데이터 분석
각 구성요소를 자세히 살펴보면, 기존의 운영시스템(운영계, 기간계, 계정계, 사무계, 사무처리계 등)의 구조화된 데이터는 ETL(Extraction Transformation Load) 도구를 이용하여 DW Platform으로 수집합니다. Hadoop Platform으로 수집은 Hadoop Eco System에서 제공하는 도구(Sqoop, Flume 등)들을 활용합니다. ETL 도구에서도 비구조적 데이터를 수집하는 방법을 제공합니다.
DW Platform에서 필요한 비구조적 데이터는 분석에 필요한 수준으로 요약하거나 Hadoop 환경에서 분산 병렬 처리된 데이터 결과들을 DW Platform으로 적재하여 분석에 활용하도록 합니다. Hadoop Platform에서도 DW Platform의 데이터가 필요할 수 있습니다.
DW Platform에는 전사 조직, 고객, 상품 등에 대한 마스터 데이터가 정비되어 있고, 운영시스템에서 발생한 상세 레벨의 데이터들도 있으므로 Hadoop Platform에서 데이터 처리할 때 이런 데이터들을 활용할 수 있습니다.
또 DW Platform에는 대용량의 데이터가 있으므로 데이터 수명 주기에 따라 사용도가 낮은 데이터들은 백업 시스템이나 ILM(Information Lifecycle Management) 시스템으로 아카이빙을 합니다. 이 때 Hadoop Platform을 DW Platform의 아카이빙 시스템으로 활용도 가능합니다.
Data Virtualization(데이터 가상화)은 물리적으로 데이터를 보유하는 것이 아니라 활용에 필요한 데이터를 DW Platform과 Hadoop Platform으로부터 가져와서 분석에 활용이 가능하게 합니다. 그러나, 대용량 데이터 처리가 필요한 경우나 데이터 표준화 수준이 낮을 경우에는 다른 대안을 검토할 필요도 있습니다.
Analytics Platform은 OLAP(On-Line Analytical Process), Data Visualization(데이터 시각화), EIS(Executive Information System), MIS(Management Information System), Reporting 도구 등을 활용하여 데이터 분석을 지원합니다.
HIA 적용 사례를 통한 금융권 적용 방안
금융분야는 아니지만 제조업과 통신업에 적용된 사례를 통해 금융권으로의 적용 가능성을 확인해 보고자 합니다. 다수의 사례들이 있지만 Gartner에서 조사한 운영 및 재무성과 개선 영역에 대한 2가지 사례를 공유해 보겠습니다.
먼저 테이프로 관리하던 과거 이력 데이터를 Hadoop 시스템을 아카이빙으로 활용한 사례입니다. 공정 프로세스상에서 발생하는 대량의 데이터를 상용 RDBMS에서 보관하기에는 고비용이어서 3개월 이후의 데이터는 테이프로 보관하고 필요 시 테이프의 데이터를 복구하여 서비스하였습니다.
그러나, 필요한 데이터를 테이프로부터 복구하고 분석하여 대응하기에는 10여일 이상이 필요하여 적시 대응이 어려웠습니다. 이런 과거 이력 데이터들을 Hadoop 시스템에 적재한 후 바로 조회를 할 수 있도록 하여 과거 품질에 대한 데이터를 1일 이내에 조회할 수 있게 되었습니다. 더불어 과거 이력 데이터 분석에 대한 업무 효율성과 연계 분석까지 가능한 기반을 마련하였습니다.

l 장기 데이터 보관 Hadoop 도입 전과 후

l 장기 데이터 아카
이빙 시스템으로 Hadoop 도입 효과
이번엔 대용량 데이터를 이용해 과금처리 배치 작업을 Hadoop 환경에서 구현한 통신 사례를 살펴보겠습니다. CDR(Call Data Record)은 통화를 하거나 문자를 송수신하는 경우 발생하는 기본 데이터입니다. CDR을 기초로 통화 시간을 계산하고 문자 송수신 건수를 계산하여 고객별로 과금을 하게 됩니다.
기존에는 DW 시스템을 이용하여 과금 계산 배치 프로그램을 수행하였으나, 시간이 오래 걸리고 배치 작업 시 CPU와 메모리를 많이 필요로 하여 다른 작업에 많은 영향을 주었습니다.
전체 배치 프로세스 중에서 과금에 필요한 데이터만 Hadoop에 적재하고 분산 병렬 처리 배치 프로그램을 통해 배치 시간을 획기적으로 줄이고, CDR 배치 작업의 부하가 기존 DW 시스템에서 제거됨에 따라 DW 시스템의 자원에 여유가 생겨 전체 배치 작업 시간 단축과 서버 활용도를 높이는 부가적인 효과도 거두었습니다.

l 과금 처리를 위한 CDR 배치 작업을 Hadoop 시스템에서 실행

l CDR 배치 작업의 Hadoop 실행 효과
위 2가지 사례를 바탕으로 금융권에 적용 가능한 업무를 살펴보겠습니다. 기존 정보계에 저장하기에는 부담스러운 과거 이력 데이터들이 있으며 이런 데이터들을 상용 RDBMS에서 저장하도록 구성하기에는 많은 비용이 필요하나 Hadoop 환경을 이용하면 상대적으로 적은 비용 범위 내에서 조회 환경을 구성하게 됩니다.
모든 금융권에는 ILM(Information Lifecycle Management) 시스템이 있습니다. ILM SW 도입 비용과 저가의 디스크로 인프라를 구축한다고 하더라도 Hadoop 보다는 고가일 것으로 예상됩니다. 따라서 ILM의 일부 역할을 Hadoop 환경으로 대체할 수 있습니다.
야간에 실행되는 배치 프로그램을 보면 전체 Critical Path에 서 대용량의 데이터가 필요하고 업무 로직이 복잡하여 전체 배치 시간에 영향을 주는 프로그램들이 있습니다.
이런 배치들을 Hadoop 환경으로 이관하여 작업하고 최종 결과물을 DW 시스템으로 다시 가져와서 활용한다면 전체 배치 시간을 단축할 수 있습니다. (ex. 리스트 시스템의 고객 신용 평가, CRM의 고객 등급 평가, 사기 탐지 시스템의 탐지 로직 등)
이 외에도 과거에는 활용하기 힘들었던 고객 관련 각종 로그 데이터(웹 로그, 모바일 로그, Click Stream 등)를 추가해 고객에 대한 전체적 데이터를 가지고 마케팅•영업 증대를 위해 활용 가능합니다. 그래서, 고객의 구매 이력 데이터를 머신 러닝으로 패턴을 분석하여 기존의 추천 서비스보다 세부화된 추천 서비스도 제공할 수 있습니다.
일부 카드사에서는 파일럿으로 고객 추천 세부화에 대한 검증과 가능성을 확인하였습니다. 또한 사기와 관련 유사 패턴을 도출하여, 보험의 FDS(Fraud Detection System)의 효율을 개선한 사례도 나오고 있습니다. 그 밖에도 HIA 환경을 통해 아래와 같은 분야에서 활용이 가능합니다.

l HIA 기반 빅데이터 활용 분야
HIA 도입에 따른 기대효과
HIA는 다양성, 운영비용 절감, 확장성, 신속성 측면에서 기대효과를 볼 수 있습니다.

l HIA 도입 효과
기대효과를 상세히 살펴 보면, 빅데이터의 기반 인프라인 Hadoop은 x86 Linux기반으로 증설 필요 시 x86서버들을 추가 연결해 주면 됩니다. 따라서, Unix기반의 상용 시스템 대비 증설에 따른 부담이 감소하고, 관련 SW들도 OSS(Open Source Software)가 많아 SW사용에 따른 라이선스 비용이 상대적으로 저렴합니다.
Hadoop 시스템의 성능은 Scale-out 방식으로 이루어집니다. 상용 서버들의 성능 향상을 위해서는 서버 내에서 메모리 증설, CPU추가, 고성능 CPU로의 교체 등을 통해 성능 향상을 꾀합니다. 이런 방식을 Scale-up이라고 합니다.
Scale-up은 서버 내에서 이루어지므로 노후된 서버는 메모리 증설에 한계가 있으며 CPU의 단종 등으로 성능 향상에 한계가 있습니다. 반면에 Scale-out은 x86서버들을 병렬로 추가하여 병렬도를 높이는 방식으로 성능을 향상할 수 있습니다. 따라서 고성능이 필요할 경우, x86서버들을 추가해주면 원하는 성능을 얻을 수 있습니다
Hadoop 시스템은 작업 처리를 병렬로 처리하는 구조입니다. 수 억건 이상의 데이터를 다루는 경우, Hadoop 시스템의 병렬 처리 특성을 이용하면 전체 배치 시간을 단축할 수 있습니다. 예를 들어 리스크 관리 시스템에서 고객의 리스크 점수를 계산하는 프로그램이나 CRM에서 고객 신용도를 평가하는 프로그램의 경우, 모든 고객 데이터들의 실적을 기반으로 작업을 해야하므로 서버에 상당한 부하가 발생합니다. 이런 작업들은 Hadoop을 활용하면 짧은 시간 내에 완료할 수 있습니다.
빅데이터 분석 목적은 기존에 분석할 수 없었던 비구조화 데이터들의 분석입니다. 저렴한 Hadoop 인프라에 비구조화된 데이터들을 축적하고, 기존 정보계 시스템인 DW데이터들과 병합하여 분석하면, 과거에 힘들었던 새로운 관점으로 데이터 분석이 가능해집니다. 또한, 전사에서 보유하고 있는 데이터의 활용도와 효율성이 증대합니다.
역할과 기능 검증을 넘어 본격 활용 단계로
금융권에서는 10억 미만 규모의 Pilot 프로젝트들을 통해 빅데이터에 대한 역할과 기능 검증을 하고 있으며, 일부 금융사에서는 실제 업무에 적용하여 효과를 체험하는 등 적용사례가 늘어나고 있습니다.
Hadoop 관련 기술들도 OSS(Open Source Software)라는 불안감을 불식시키는 한편 기업에서 필요로 하는 보안, 자원관리, 가용성 보장 등이 가능해지고 있으며, 메모리상에서 작동하는 Spark 기술도 발전하고 있습니다. IT 개발자들에게 가장 친숙한 언어인 SQL(Structured Query Language)을 Hadoop에서 지원하는 SQL on Hadoop 기술의 발전도 Hadoop 환경 확산에 기여하고 있습니다.
내년과 내후년에도 HIA 기반의 대형 적용사례들이 늘어날 것으로 예상되는데요. 빅데이터의 본격 활용 시대가 머지 않은 것 같습니다. 여러분도 기대해 주십시오.
출처 : https://blog.lgcns.com/1775?category=515147
인공지능과 빅데이터를 위한 정보 분석 아키텍처 1편, LDW
IDC는 2020년, 전 세계 데이터가 44 제타바이트에 이를 것으로 전망했습니다. 모바일, 소셜 미디어, IoT 등 디지털 기술의 발달로 데이터는 폭증하고 있는데요. 발생 데이터 80% 이상이 비정형 데이터로 그 종류도 다양합니다. 바야흐로 데이터의 빅뱅, 빅데이터 시대라 할 수 있습니다. 하지만 기존 정보 분석 환경은 정형 데이터를 기본으로 하고 있어, 다양하고 방대한 양의 데이터 처리가 어려운 실정입니다.
오픈소스의 발달로 빅데이터 처리가 가능해진 하둡(Hadoop)의 등장에 따라 저렴한 비용으로 대량의 데이터를 저장할 수 있게 되었고, 분산 병렬 처리를 지원하여 빅데이터 처리와 분석이 가능하게 되었습니다.
기업들은 이미 구축해 각종 분석에 활용하고 있는 정형 데이터 중심의 데이터 웨어하우스(Data Warehouse) 시스템과 비정형 데이터의 저장뿐 아니라 대량의 정형 데이터를 분산 병렬 처리해 분석할 수 있도록 지원해 주는 하둡 환경과의 통합을 요구하고 있는데요. 기존의 데이터 웨어하우스와 빅데이터의 핵심 기술인 하둡을 통합해 추상화한 정보 분석 아키텍처로서 가트너(Gartner)에서 제시한 개념이 로지컬 데이터 웨어하우스(Logical Data Warehouse)입니다.
LDW(Logical Data Warehouse)의 정의
정형 데이터뿐만 아니라 비정형 데이터까지 분석 가능한 데이터 관리 아키텍처로, 기존의 EDW(Enterprise Data Warehouse)를 포함하는 상위 아키텍처입니다. 시장에서는 Hybrid DW(Data Warehouse)라고도 하며 LG CNS에서는 HIA(Hybrid Information Architecture)라고 불리고 있습니다
LDW 즉, 로지컬 데이터 웨어하우스의 등장 배경은 다음과 같습니다.
- 스마트 환경의 도래로 개인들이 생산하는 소셜 정보, 음성, 영상, 이미지 데이터의 폭증
- 다양한 내•외부 IoT 데이터를 연계하여 분석할 필요성 대두
- 운영 시스템의 기능이 복잡해지고, 활용이 증가함에 따라 IT시스템으로부터 생성되는 데이터 급증
- 각종 시스템으로부터 발생되는 대량의 로그성 데이터들을 저장하기에는 비용이 많이 필요하였으나, 저가의 디스크를 이용한 저장이 가능해지면서, 과거에는 활용하지 못하던 로그성 데이터들에 대한 활용 요구 증가
- OSS(Open Source Software)의 성숙도가 향상되고, 분산 병렬 처리를 지원하는 다양한 소프트웨어들이 출시되면서 저렴한 비용으로 대용량 처리를 할 수 있는 기반이 갖추어짐
로지컬 데이터 웨어하우스는 기존의 데이터 웨어하우스와 다른 개념이 아니라 빅데이터 기술을 포함하는 확장된 개념으로 과거에는 비용과 처리 속도 등으로 분석하지 못하던 데이터까지 분석할 수 있도록 지원합니다.
로지컬 데이터 웨어하우스가 가지는 중요한 특징은 아래와 같습니다.
- 비용 절감: DBMS에 저장하기에 비용이 과다한 데이터들은 오픈소스 기반의 Hadoop을 이용하여 상대적으로 저렴하게 관리가 가능하며, 하드웨어•소프트웨어 증설에 따른 비용 절감 가능
- 분석의 적시성 확보: 대용량 데이터의 신속한 분산 병렬 처리를 통한 장시간 소요되던 배치 작업 시간을 단축하여 분석에 필요한 데이터들의 적시 제공 가능
- 데이터 효용성 증대: 데이터 웨어하우스에서 관리되는 고품질의 정형 데이터들과 비정형 데이터를 결합하여 분석이 가능함에 따라 데이터의 효용성 증대
- Scale-Out이 가능한 인프라 구성: 하둡 기반의 빅데이터 시스템들은 Scale-out을 통한 선형적인 성능 향상이 가능, LDW는 이런 오픈소스 기반의 기술을 활용하여 성능 확보 가능
기존 데이터 웨어하우스에 익숙한 사람들의 이해를 돕기 위해 빅데이터를 포함하는 로지컬 데이터 웨어하우스를 활용 목적, 데이터 특징, 주 사용자 및 기술 측면에서 비교해 보았습니다.
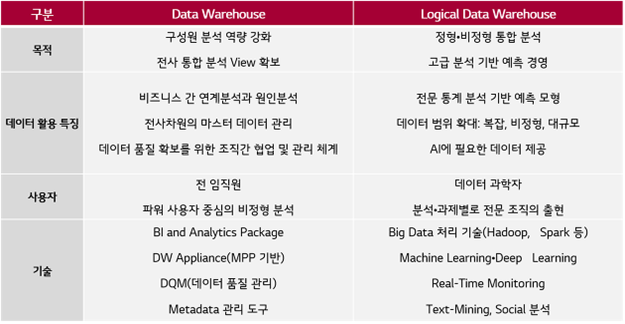
l 데이터 웨어하우스와 로지컬 데이터 웨어하우스의 비교
LDW(Logical Data Warehouse)의 구성 요소
가트너에서는 아래와 같이 로지컬 데이터 웨어하우스의 구성 요소들을 추상화해 아래와 같이 표현합니다.

l 로지컬 데이터 웨어하우스 구성도
● Repository Management
- 컴플라이언스 이슈나 법규, 법령 관련한 보고서들에 대한 데이터들은 고품질의 데이터가 필요하므로 세밀한 관리가 필요함
- 정부 기관이나 상위 기관에 데이터를 제공하기 위해서는 RDBMS나 데이터 웨어하우스 전용 DBMS에 데이터를 저장하여 관리함
- 대량으로 발생하는 센서 데이터, 비정형 데이터들은 저장 비용과 데이터 처리 성능을 고려해 Repository로 HDFS(Hadoop Distributed File System)를 사용 가능함
● Data Virtualization
- 데이터 타입(문자, 숫자, 날짜 등), 데이터의 위치, 데이터 구조(정형, 반정형, 비정형)에 상관없이 분석에 필요한 데이터들의 Single View를 제공하는 기술
- 데이터는 원천에 있으면서 가상의 View를 통한 데이터 활용이 가능
- 대량의 데이터 처리가 필요한 경우 Data Virtualization Layer의 병목이 발생 가능할 수 있으므로 성능 개선이나 타당성에 대한 검토가 필요함
● Distributed Processing
- 대량의 데이터에 대해 분석 작업과 질의 작업을 위해서는 하나의 서버로 처리가 불가능함
- 서버 자원의 분산처리, 데이터에 대한 분산 처리를 통해 대량 데이터 처리가 가능
- 데이터를 여러 개의 디스크로 파티션하여 저장할 수도 있음
- 분산 처리가 완료된 후 그 결과들은 하나로 취합되어 요청자에게 전달됨
● Metadata Management
- 로지컬 데이터 웨어하우스에서 활용되고 관리되는 모든 데이터의 메타 데이터들의 관리는 매우 중요함
- 메타 데이터의 종류는 기술적 메타 데이터, 업무적 메타 데이터, 정보 메타 데이터로 구분할 수 있음
- 기술적 메타 데이터는 로지컬 데이터 웨어하우스의 개별 시스템으로 발생하는 메타 데이터로 Data Virtualization에서 생성되는 메타 데이터가 예가 될 수 있음
- 업무적 메타 데이터는 사용자 관점에서 업무에 필요한 메타 데이터로 데이터에 대한 정의로 볼 수 있음(예, 매출에 대한 정의, 비용에 대한 정의 등)
- 정보 메타 데이터는 데이터의 원천에서부터 활용까지 이어지는 데이터 흐름에 대한 정보를 말함
- 메타 데이터는 데이터 품질관리, 마스터 데이터 관리, 데이터 거버넌스 등에 중요함
● Taxonomy•ontology resolution
- 연관된 데이터들을 결합해서 분석하기 위해 필요한 데이터 간 연관 정보, 데이터 집합에 대한 분류 체계들을 의미함
- Metadata management에서 언급한 메타 데이터 분류 중 정보 메타 데이터에 해당함
● Auditing and performance services
- 데이터 원천으로부터 데이터를 추출하여 분석 목적에 적합하도록 가공하고 repository에 저장하는 일련의 처리 작업과 이런 처리 작업의 정해진 시간에 종료하기 위한 성능 개선 작업을 말함
- 데이터의 생성부서 최종 사용자에게 제공되는 모든 과정은 모니터링되고 각 단계에 대한 로그는 관리되어 향후 서비스 개선에 활용
● SLA management
- 데이터 웨어하우스의 데이터를 분석하고 질의를 하는 사용자들의 서비스 수준을 관리(분석 성능, 리포트 조회 성능, 데이터 정합성 수준 등)
- 고품질의 로지컬 데이터 웨어하우스 데이터를 활용하는 시스템(CRM, 사기탐지, 리스크 관리, 자금세탁방지 등)에 대한 적시, 적기에 필요 데이터 제공 서비스
LDW(Logical Data Warehouse) 아키텍처
로지컬 데이터 웨어하우스 구성도를 데이터 원천부터 활용에 이르기까지 구체적으로 정의하면 아래와 같은 연계 아키텍처로 표현할 수 있으며, 로지컬 데이터 웨어하우스는 붉은 선으로 둘러싸인 영역입니다.

l 로지컬 데이터 웨어하우스 연계 아키텍처
● Data Source
- Smart Device로부터 발생하는 다양한 정형 비정형 데이터들과 기업 내부에서 발생하는 운영 데이터들이 대상이다.
● Data Collect
- Data Source로부터 필요한 데이터들은 내•외부망을 통해 수집하며, 수집에 사용되는 기술은 대표적으로 ETL(Extraction, Transformation, Loading)과 CDC(Change Data Capture)가 있다.
● Data Store & Computing: 실제 LDW 영역
- 실시간 처리나 연속적으로 수집되는 데이터들에 대해서는 Event 처리 기술을 응용하여 대응이 가능하다.
- IoT 데이터들의 구성 항목은 업무 데이터들에 비해 단순하나, 센서 개수에 비례하여 데이터양이 폭증하므로 빅데이터 플랫폼에 저장하여 활용이 가능하다.
- 최근에는 기업 내에서 발생하는 모든 데이터를 저장•관리하는 Data Lake가 관심을 끌고 있는데, Data Lake를 효과적으로 활용하기 위해서는 관심 대상이 되는 데이터들에 대한 거버넌스가 필수적이다. 이를 제대로 활용하기 위해서는 어떤 데이터들이 있으며, 그 데이터의 수준과 품질은 어떻게 되는지 파악을 할 수 있어야 분석할 수 있기 때문이다.
- DW 플랫폼은 운영 시스템에서 발생하는 데이터들을 ETL을 활용하여 수집하고, 다양한 분석에 데이터들을 제공하는 역할을 담당한다. 기업 내 핵심 마스터 데이터들도 DW 플랫폼에 취합되므로, 이런 표준 데이터들은 빅데이터 플랫폼에 공유되어 활용할 수 있도록 하고, 10년 이상 된 DW 플랫폼의 데이터는 효율적인 DW 플랫폼의 저장 공간 활용을 위해 빅데이터 플랫폼을 archive 영역으로 활용이 가능하다.
● Application
- 빅데이터 플랫폼과 DW 플랫폼에 저장•관리되는 데이터들은 다양한 영역에서 응용할 수 있다.
● Data Analysis
- 원천으로부터 수집되어 가공된 데이터들은 고급 분석, 통계 분석 등에 활용이 가능하고 시각화 분석을 할 수 있다.
로지컬 데이터 웨어하우스의 연계 아키텍처는 다양한 활용 방안을 포괄하고 있습니다. 세부적으로 활용 유형을 정리해 보면 다음과 같습니다.
● IoT 플랫폼
- 다양한 센서들, 스마트 디바이스로부터 발생하는 데이터 중심으로 빅데이터 플랫폼을 구성하고, 여기에 수집된 데이터들은 M2M 기반 서비스, 에너지 서비스 등 IoT 서비스 플랫폼에서 활용할 수 있다.
● Hybrid DW
- 규모가 큰 기업들은 보고서 작성과 분석 목적으로 DW를 보유하고 있다.
● Data Analytics
- 분석에 필요한 모든 데이터를 취합하여 제공하는 역할을 담당한다.
● Data Virtualization
- 별도의 가상화 도구를 활용하여 실제 데이터들은 각각 두고, 필요 시점마다 데이터를 취합하여 활용할 수 있다.

l 로지컬 데이터 웨어하우스 연계 아키텍처의 활용 유형
지금까지 로지컬 데이터 웨어하우스의 개요와 특징 그리고, 로지컬 데이터 웨어하우스는 어떻게 구성되는지에 대해 알아봤습니다. 이어서 다음 시간에는 로지컬 데이터 웨어하우스의 적용 사례에 대해 알아보겠습니다.
출처 : https://blog.lgcns.com/1788?category=515147
인공지능과 빅데이터를 위한 정보 분석 아키텍처 2편, LDW
2018.08.14 09:30
지난 시간에는 인공지능과 빅데이터를 위한 정보 분석 아키텍처 로지컬 데이터 웨어하우스(Logical Data Warehouse)의 정의와 구성 요소에 대해 알아봤습니다. 이번 시간에는 로지컬 데이터 웨어하우스의 적용 사례와 동향에 대해 알아보겠습니다.
● 인공지능과 빅데이터를 위한 정보 분석 아키텍처: http://blog.lgcns.com/1775
LDW(Logical Data Warehouse)의 적용 사례
LDW라는 개념은 2~3년 전에 제시되었고, 다양한 활용 사례들이 있는데요. 그중에서 빅데이터 기술을 활용해 저렴한 저장 공간을 활용한 사례와 분산 병렬 처리를 이용한 배치 속도 개선 사례를 함께 알아보겠습니다.
● 데이터 아카이빙 영역으로 빅데이터 플랫폼 활용
생산 공정 과정에서 발생하는 대부분 데이터는 용량이 과다해 3개월 이후에는 테이프로 백업 받아서 보관되는데요. 3개월이 지난 공정 데이터에 대한 품질 확인이 필요한 경우에는 백업 테이프를 검색하고 다시 복구해야 하는데 이 과정에 2주 정도가 소요됩니다. 이러한 데이터 아카이빙 영역에 빅데이터 플랫폼 기술인 하둡(Hadoop)을 활용해 개선할 수 있습니다.

l 데이터 아카이빙으로 빅데이터 플랫폼 활용
하둡 빅데이터 플랫폼을 활용하게 되면 장기 이력 데이터에 대한 사용자 상세 분석 시간을 기존 15일 이상 소요되던 것을 1일 이내로 단축할 수 있고, 저가의 디스크 활용으로 75% 비용으로 구축할 수 있습니다. 그뿐만 아니라 최근 데이터와 이력 데이터와의 연계 분석도 가능해집니다.
● 대용량 배치처리를 빅데이터 플랫폼에서 실행
빅데이터 플랫폼은 분산 병렬 처리에 장점이 있습니다. 기존 시스템에서 장기간 소요되는 배치 작업을 빅데이터 플랫폼에서 실행하고 그 결과를 DW 플랫폼에 제공해 전체 배치 시간을 획기적으로 단축할 수 있습니다. 매일 수백 GB 단위로 발생하는 데이터에 대한 처리는 하둡을 통해 가능합니다.

l 빅데이터 플랫폼을 활용한 배치 성능 개선
대용량 배치 처리를 하둡 빅데이터 플랫폼에서 실행할 경우 기존 DW 플랫폼으로 동일 성능을 확보하는 데 필요한 비용 대비 1/4 비용으로 구성할 수 있고, 전체 작업은 시간은 60% 단축될 수 있습니다.
작업 시간의 단축은 DW 데이터의 적시성 확보를 가능하게 하여 의사결정이 신속해졌고, VOC 대응이나 고객 이상 징후에 대한 신속한 대응으로 고객만족도 역시 향상될 수 있습니다.
LDW(Logical Data Warehouse)의 동향
● LDW 관련 Hype Cycle

l Hype Cycle for Analytics and Business Intelligence, 2017
2017년 7월에 발표한 가트너의 ‘Hype Cycle for Analytics and Business Intelligence, 2017’을 보면 LDW는 환멸 단계(Trough of Disillusionment)를 지나고 있으며, 조금씩 사례들이 나오고 지원 솔루션들이 개선되면서 계몽 단계로 진입할 것으로 예상합니다.
마이크로소프트(MicroSoft)는 SQL Server를 기반으로 하둡을 연계하는 아키텍처를 제시하고 있으며, 클라우드 서비스인 MS Azure에서는 빅데이터 기술인 HD Insights 서비스를 제공하고 있습니다.
전통적으로 대용량 처리의 강자인 테라데이터(Teradata)는 SQL-H, Aster 등을 기반으로 UDW 아키텍처를 제시하고 있으며, 운영 DBMS의 최강자인 Oracle은 DW 전용 Appliance인 Exadata와 하둡 플랫폼의 선두 업체인 클라우데라(Cloudera)를 기반으로 BDA를 시장에 출시해 다수의 고객사를 확보하고 있습니다.
● Microsoft Analytics Platform system
마이크로소프트는 Polybase를 이용하여 SQL 서버와 빅데이터 플랫폼인 하둡과 인터페이스를 하는 아키텍처로 구성됩니다. 빅데이터 플랫폼으로는 홀튼웍스(Hortonworks) 제품과 클라우데라를 지원합니다.

l Microsoft Analytics Platform
● Teradata UDW(Unified Data Warehouse)
테라데이터는 전통적으로 대형 전문 DW 솔루션을 보유하고 있는 업체입니다. 하둡까지 솔루션 영역을 확대해 데이터 수집부터 분석 및 사용자의 활용까지 지원하는 다양한 모듈을 제공하고 있습니다.
● Oracle Big Data Appliance
오라클(Oracle)은 빅데이터 플랫폼 업체인 클라우데라 제품과 통합한 BDA(Big Data Appliance)를 제공하고 있습니다. 기존의 DW Appliance인 Exadata를 채택한 고객사가 많아 전체 제품 통합 차원에서 선호되는 아키텍처입니다.

l Oracle BDA
최근 LDW는 빅데이터 플랫폼 솔루션의 성숙도가 향상되고, 보안에 대한 불안감이 해소되면서 확대되는 추세로, LG그룹사는 다양한 형태의 LDW를 이미 구축했거나 구축 중입니다.
공공시장은 대기업 참여 제한이 풀리면서 이미 구축한 DW를 고도화하면서 빅데이터 플랫폼과 통합한 아키텍처 도입을 검토하고 있고, 금융권도 LDW를 적극적으로 검토하고 있습니다.
PoC나 Pilot 단계를 지나 운영 시스템으로 LDW를 도입 중인 은행들이 증가하고 있으며, 카드 및 보험 업계에서도 구축에 대한 구체적인 고민을 시작하고 있습니다. 그뿐만 아니라, 과거에 DW를 구축한 회사들도 LDW로 점차 전환할 것으로 예상하고 있습니다.
인공지능의 핵심 기술로 주목을 받는 딥러닝을 위해서는 LDW가 필요하고, 빠른 학습을 위해서는 GPU(Graphic Process Unit) 기반의 아키텍처가 필요하므로 빅데이터 기술뿐만 아니라 GPU 기술까지 포괄하는 아키텍처로 발전이 예상됩니다.
NLU(Natural Language Understanding)를 위해서는 다양한 케이스의 데이터들이 필요하며, NLU의 기반으로도 LDW의 역할이 중요해질 것으로 보입니다.
하둡 에코 시스템
Hadoop Echosystem
하둡은 다양한 서브 프로젝트가 개발되면서 하둡 에코시스템(하둡 생태계)이 구성되었다. 분산 데이터를 저장하는 HDFS와 분석 데이터를 처리하는 맵리듀스가 하둡의 메인(코어) 프로젝트에 해당하며 나머지 프로젝트는 하둡의 서브 프로젝트로 관리 및 수집 등의 기능을 한다.

(출처 : 시작하세요 하둡 프로그래밍 / 위키북스 http://blrunner.com/?page=13)
[Zookeeper]
분산 환경에서 서버간의 상호 조정이 필요한 다양한 서비스 제공. 로드 밸런스, 동기화, HA 등 분산환경을 구성하는 서버들의 환경설정을 통합적으로 관리
[Oozie]
하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템. 자바 서블릿 컨테이너에서 실행되는 자바 웹 어플리케이션이며 맵리듀스 작업이나 피그 작업 같은 워크 플로우 제어.
[HBase]
HDFS 기반의 컬럼 기반 데이터베이스. 구글의 BigTable 논문을 기반으로 개발. 실시간 랜덤 조회 및 업데이트 가능. 각 프로세스는 비동기 방식으로 업데이트 가능. (맵리듀스는 일괄 방식으로 처리)
[Pig]
복잡한 맵리듀스 프로그래밍르 대체한 Pig Latin 이라는 자체 언어 제공. 맵리듀스 API를 단순화 시켰으며 SQL과 유사한 형태로 설계.
[Hive]
하둡 기반의 데이터웨어하우징용 솔루션. 페이스북에서 개발. SQL과 유사한 HiveQL 쿼리 제공. 자바를 모르는 데이터분석가들도 쉽게 하둡 데이터 분석 가능. HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행
[Mahout]
하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈 소스. Classfication, clustering, Regression, Dimension Reduction, Evolutionary Algorithms 등 알고리즘 지원.
[HCatalog]
하둡으로 생성한 데이터를 위한 테이블 및 스토리지 관리 서비스. 가장 큰 장점은 HCatalog를 이용하면 Hive에서 생성한 테이블이나 데이터 모델을 Pig나 맵리듀스에서 쉽게 활용 할 수 있어 하둡 에코시스템 간의 상호 운용성 향상된다.
[Avro]
데이터 직렬화를 지원하는 프레임워크. JSON을 이용해 데이터 형식과 프로토콜을 정의하며 작고 빠른 바이너리 포맷으로 데이터를 직렬화 한다.
[Chukwa]
분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장하는 플랫폼. 각 서버의 Agent로부터 데이터를 받아 HDFS에 저장. 콜렉터는 100개의 Agent 당 하나씩 구동되며 데이터 중복 제거 등 맵리듀스로 처리한다.
[Flume]
척와(Chukwa)처럼 분산도니 서버에 에이전트가 설치되고 에이전트로부터 데이터를 전달 받는 콜렉터로 구성. 전체 데이터 흐름을 관리하는 마스터 서버가 있어 데이터의 수집 및 저장 위치를 동적으로 변경 가능하다.
[Scribe]
척와와는 다르게 중앙으로 데이터를 전송하는 방식. 최종 데이터는 HDFS외에 다양한 저장소를 활용할 수 있으며 설치와 구성이 쉬우며 다양한 프로그래밍 언어를 지원. HDFS에 저장하려면 JNI(Java Native Interface)를 사용해야 한다.
[다양한 에코시스템]



출처 : https://blog.naver.com/rock1192/220989196800
하둡 에코시스템
- 하둡은 비즈니스에 효율적으로 적용할 수 있게 다양한 서브 프로젝트를 제공한다
- 이러한 서브 프로젝트가 상요화되면서 하둡 에코시스템(Hadoop Ecosystem)이 구성됨
- 하둡 생태계라고 표현하기도 함
- 분산 데이터를 저장하는 HDFS와 분석 데이터를 처리하는 맵리듀스가 하둡 코어 프로젝트에 해당함
- 나머지 프로젝트는 모두 하둡의 서브 프로젝트임
|
워크플로우 |
데이터 |
대화형 질의 처리 |
데이터 웨어하우스 |
||
|
스크립트 처리 |
머신러닝 |
인메모리 처리 |
|||
|
분산 데이터 배치 처리 |
분산 클러스터 리소스 관리 |
||||
|
분산 코디네이터 |
데이터 |
||||
|
분산 데이터베이스 |
칼럼 기반 스토리지 |
||||
|
분산 데이터 저장 |
|||||
|
스트리밍 데이터 수집 |
DBMS 데이터 수집 |
분산 메시지 처리 |
|||
|
|
|||||
▶ 코디네이터
■ Zookeeper(http://zookeeper.apache.org)
- 분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템
- 크게 다음과 같은 네가지 역할을 수행함
- 첫째, 하나의 서버에만 서비스가 집중되지 않게 서비스를 알맞게 분산해 동시에 처리하게 해줌
- 둘째, 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해서 데이터의 안정성을 보장함
- 셋째, 운영(active) 서버에 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영 서버로 바꿔서 서비스가 중지 없이 제공되게 함
- 넷째, 분산 환경을 구성하는 서버의 환경설정을 통합적으로 관리
▶ 리소스 관리
■ 얀(YARN)(http://hadoop.apache.org)
- 데이터 처리 작업을 실행하기 위한 클러스터 지원(CPU, 메모리, 디스크 등)과 스케쥴링을 위한 프레임워크
- 기존 하둡의 데이터 처리 프레임워크인 맵리듀스의 단점을 극복하기 위해 시작된 프로젝트
- 하둡2.0부터 이용할 수 있음
- 맵리듀스, 하이브, 임팔라, 타조, 스파크 등 다양한 애플리케이션들은 안에서 리소스를 할당받아서 작업을 실행하게 됨
■ 메소스(Mesos)(http://mesos.apache.org)
- 클라우드 인프라스트럭처 및 컴퓨팅 엔진의 다양한 지원(CPU, 메모리, 디스크)을 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트
- 2009년 버클리 대학에서 Nexus 라는 이름으로 시작된 프로젝트임
- 2011년 메소스라는 이름으로 변경됐으며, 현재는 아파치 최상위 프로젝트로 진행 중
- 클러스터링 환경에서 동적으로 자원을 할당하고 격리하는 메커니즘을 제공하며 이를 통해 분산 환경에서 작업 실행을 최적화할 수 있음
- 1만 대 이상의 노드에도 대응 가능하며, 웹 기반 UI, 자바, C++, 파이썬 API를 제공
- 하둡, 스파크(Spark), 스톰(Storm), 엘라스틱 서치(Elastic Search), 카산드로(Cassandra), 젠킨스(Jenkins)등 다양한 애플리케이션 을 메소스에서 실행할 수 있음
▶ 데이터 저장
■ H베이스(HBase)(http://hbase.apache.org)
- HDFS 기반의 칼럼 기반 데이터베이스
- 구글의 빅테이블(BigTable) 논문을 기반으로 개발됨
- 실시간 랜덤 조회 및 업데이트가 가능하며, 각 프로세스는 개인의 데이터를 비동기적으로 업데이트할 수 있음
- 단, 맵리듀스는 일괄 처리 방식으로 수행됨
■ 쿠두(Kudu)(http://getkudu.io)
- 컬럼 기반의 스토리지로서, 특정 컬럼에 대한 데이터 읽기를 고속화할 수 있다
- 기존에도 HDFS에서도 파케이(Parquet), RC, ORC와 같은 파일 포맷을 사용하면 컬럼 기반으로 데이터를 저장할 수 있지만
HDFS 자체가 온라인 데이터 처리에 적합하지 않다는 약점이 있었음
- HDFS 기반으로 온라인 처리가 가능한 H베이스의 경우 데이터 분석 처리가 느리다는 단점이 있었음
- 쿠두는 이러한 문제점을 보완해서 개발한 컬럼 기반 스토리지이며, 데이터의 발생부터 분석까지의 시간을 단축할 수 있음
▶ 데이터 수집
■ 척와(Chukwa)(http://chukwa.apache.org)
- 분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장하는 플랫폼
- 분산된 각 서버에서 에이전트(agent)를 실행하고, 콜렉트(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장
- 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 맵리듀스로 처리함
- 야후에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있음
■ 플럼(Flume)(http://flume.apache.org)
- 척와처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜렉터로 구성됨
- 차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서 데이터를 어디서 수집하고, 어떤 방식으로 전송하고 어디에 저장할지를 동적으로 변경할 수 있음
- 클라우데라에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있음
■ 스크리브(Scribe)(http://github.com/facebook/scribe)
- 페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식
- 최종 데이터는 HDFS 외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원함
- HDFS에 저장하려면 JNI(Java Native Interface)를 이용해야 함
■ 스쿱(Sqoop)(http://sqoop.apache.org)
- 대용량 데이터 전송 솔루션이며, 2012년 4월에 아파치의 최상위 프로젝트로 승격됐음
- HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송하는 방법을 제공
- Oracle, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, PostgreSQL과 같은 오픈소스 RDBMS등을 지원함
■ 히호(Hiho)(http://github.com/sonalgoyal/hiho)
- 스쿱과 같은 대용량 데이터 전송 솔루션이며, 현재 깃헙(GitHub)에 공개돼 있음
- 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원함
- 현재는 Oracle 과 MySQL의 데이터 전송만 지원함
■ 카프카(Kafka)(http://kafka.apache.org)
- 데이터 스트림을 실시간으로 관리하기 위한 분산 메세징 시스템
- 2011년 링크드인에서 자사의 대용량 이벤트처리를 위해 개발됐으며, 2012년 아파치 탑레벨 프로젝트가 됨
- 발행(publish)-구독(subscribe) 모델로 구성되어 있으며, 데이터 손실을 막기 위하여 디스크에 데이터를 저장함
- 파티셔닝을 지원하기 때문에 다수의 카프카 서버에서 메세지를 분산 처리 할 수 있으며, 시스템 안정성을 위하여 로드밸런싱과 내고장성(Fault Tolerant)를 보장함
- 다수의 글로벌 기업들이 카프카를 사용하고 있으며, 그중 링크드인은 하루에 1조1천억건 이상의 메세지를 카프카에서 처리하고 있음
▶ 데이터 처리
■ 피그(Pig)(http://pig.apache.org)
- 야휴에서 개발했으나 현재는 아파치 프로젝트에 속한 프로젝트로서, 복잡한 맵리듀스 프로그래밍을 대체할 피그 라틴(Pig Latin)이라는 자체 언어를 제공
- 맵리듀스 API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계됨
- SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하기가 어려운 편임
■ 머하웃(Mahout)(http://mahout.apache.org)
- 하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스 프로젝트
- 현재 분류(classification), 클러스터링(clustering), 추천 및 협업 필터링(Recommenders/collaborative filtering), 패턴 마이닝(Pattern Mining), 회귀 분석
(Regression), 차원 리덕션(Dimension reduction), 진화 알고리즘(Evolutionary Algorithms) 등 주요 알고리즘을 지원 함
- 머하웃을 그대로 사용할 수도 있지만 각 비즈니스 환경에 맞게 최적화해서 사용하는 경우가 많음
■ 스파크(Spark)(http://spark.apache.org)
- 인메모리 기반의 범용 데이터 처리 플랫폼
- 배치 처리, 머신러닝, SQL 질의 처리, 스트리밍 데이터 처리, 그래프 라이브러리 처리와 같은 다양한 작업을 수용할 수 있도록 설계돼 있음
- 2009년 버클리 대학의 AMPLab에서 시작 됐으며, 2013년 아파치 재단의 인큐베이션 프로젝트로 채택된 후, 2014년에 최상위 프로젝트로 승격됌
- 현재 가장 빠르게 성장하고 있는 오픈소스 프로젝트 중 하나이며, 사용자와 공헌자가 급격하게 증가하고 있음
■ 임팔라(Impala)(http://impala.io)
- 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진
- 맵리듀스를 사용하지 않고, C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여줌
- 임팔라는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있음
- 2015년말 아파치 재단의 인큐베이션 프로젝트로 채택됨
■ 프레스토(Presto)(https://prestodb.io)
- 페이스북이 개발한 대화형 질의를 처리하기 위한 분산 쿼리 엔진
- 메모리 기반으로 데이터를 처리하며, 다양한 데이터 저장소에 저장된 데이터를 SQL로 처리할 수 있음
- 특정 질의의 경우 하이브 대비 10배 정도 빠른 성능을 보여주며, 현재 오픈소스로 개발이 진행되고 있다
■ 하이브(Hive)(http://hive.apache.org)
- 하둡 기반의 데이터웨어하우징용 솔루션
- 페이스북에서 개발했으며, 오픈소스로 공개되며 주목받은 기술임
- SQL과 매우 유사한 HiveQL 이라는 쿼리 언어를 제공함
- 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줌
- HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행됨
■ 타조(Tajo)(http://tajo.apache.org)
- 고려대학교 박사 과정 학생들이 주도해서 개발한 하둡 기반의 데이터 웨어하우스 시스템
- 2013년 아파치 재단의 인큐베이션 프로젝트로 선정됐으며, 2014년 4월 최상위 프로젝트로 승격됐음
- 맵리듀스 엔진이 아닌 자체 분산 처리 엔진을 사용하며, HiveQL을 사용하는 다른 시스템과는 다르게 표준 SQL을 지원하는 것이 특징임
- HDFS, AWS S3, H베이스, DBMS 등에 저장된 데이터 표준 SQL로 조회할 수 있고, 이기종 저장소 간의 데이터 조인 처리도 가능함
- 질의 유형에 따라 하이브나 스파크보다 1.4 ~ 10배 빠른 성능을 보여줌
▶ 워크플로우 관리
■ 우지(Oozie)(http://oozie.apache.org)
- 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템
- 자바 서블릿 컨테이너에서 실행되는 자바 웹 애플리케이션 서버이며, 맵리듀스 작업이나 피그 작업 같은 특화된 액션으로 구성된 워크플로우를 제어함
■ 에어플로우(Airflow)(http://nerds.airbnb.com/airflow)
- 에어비앤비에서 개발한 워크플로우 플랫폼
- 데이터 흐름의 시각화, 스케쥴링, 모니터링이 가능하며, 하이브, 프레스토, DBMS 엔진과 결합해서 사용할 수 있음
■ 아즈카반(Azkaban)(http://azkaban.github.io)
- 링크드인에서 개발한 워크플로우 플랫폼
- 링크드인은 자사의 복잡한 데이터 파이프라인을 관리하기 위해 아즈카반을 개발했으며, 이를 오픈소스로 공개했음
- 아즈카반은 워크플로우 스케쥴러, 시각화된 절차, 인증 및 권한 관리, 작업 모니터링 및 알람 등 다양한 기능을 웹UI로 제공함
■ 나이파이(Nifi)(https://nifi.apache.org)
- 나이파이(Niagarafiles, Nifi)는 데이터 흐름을 모니터링하기 위한 프레임워크
- 여러 네트워크를 통과하는 데이터 흐름을 웹UI에서 그래프로 표현하며, 프로토콜과 데이터 형식이 다르더라도 분석이 가능함
- 데이터를 흘려보낼 때 우선순위를 제어할 수 있음
- 나이파이는 원래 미국 국가안보국(NSA)에서 개발한 기술로, NSA의 기술 이전 프로그램인 TTP를 통해 처음 외부에 공개된 오픈소스 기술임
▶ 데이터 시각화
■ 제플린(Zeppelin)(https://zeppelin.incubator.apache.org
- 빅데이터 분석가를 위한 웹 기반의 분석 도구이며, 분석 결과를 즉시 표, 그래프로 표현하는 시각화까지 지원함
- 아이파이썬(iPython)의 노트북(Notebook)과 유사한 노트북 기능을 제공하며, 분석가는 이를 통해 손쉽게 데이터를 추출, 정제, 분석, 공유할 수 있다
- 스파크, 하이브, 타조, 플링크(Flink), 엘라스틱 서치, 카산드라, DBMS 등 다양한 분석 플랫폼과 연동할 수 있다
- 2013년 엔에프랩의 내부 프로젝트로 시작됐으며, 2014년 아파치 재단의 인큐베이션 프로젝트로 선정됨
▶ 데이터 직렬화
■ 아브로(Avro)(http://avro.apache.org)
- RPC(Remote Procedure Call)와 데이터 직렬화를 지원하는 프레임워크
- JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포멧으로 데이터를 직렬화함
- 경쟁 솔루션으로는 아파치 쓰리프트(Thrift), 구글 프로토콜 버퍼(Protocol Buffer)등이 있음
■ 쓰리프트(Thrift)(http://thrift.apache.org)
- 서로 다른 언어로 개발된 모듈들의 통합을 지원하는 RPC 프레임워크
- 예를 들어, 서비스 모듈은 자바로 개발하고, 서버 모듈은 C++로 개발됐을 때 쓰리프트로 쉽게 두 모듈이 통신하는 코드를 생성할 수 있다
- 개발자가 데이터 타입과 서비스 인터페이스를 선언하면 RPC 형태의 클라이언트와 서버 코드를 자동으로 생성함
- 자바, C++, C#, 펄, PHP, 파이썬, 델파이, 얼랭, Go, Node.js 등과 같이 다양한 언어를 지원함
출처 : https://blog.naver.com/koalagon/110154795556
하둡은 비즈니스에 효율적으로 적용할 수 있도록 다양한 서브 프로젝트가 제공됩니다. 이러한 서브 프로젝트들이 상용화되면서, 하둡 에코 시스템(Hadoop ECO system)이 구성됐습니다. 참고로 하둡 에코 시스템은 하둡 생태계라고 표현되기도 합니다. 아래 그림은 하둡 에코 시스템을 나타낸 것입니다. 분산 데이터를 저장하는 HDFS와 분석 데이터를 처리하는 MapReduce가 하둡 코어 프로젝트에 해당하며, 나머지 프로젝트는 모두 하둡의 서브 프로젝트입니다. 아파치 하둡 프로젝트에 속하는 프로젝트도 있지만, 업체에서 자사의 솔루션으로 이용하다가 오픈 소스로 공개한 프로젝트도 있습니다.

각 각의 서브 프로젝트들의 특징은 다음과 같습니다.
1. Zookeeper
분산 환경에서 서버들간에 상호 조정이 필요한 다양한 서비스를 제공하는 시스템입니다. 첫째, 하나의 서버에만 서비스가 집중되지 않도록, 서비스를 알맞게 분산하여 동시에 처리하게 해줍니다. 둘째, 하나의 서버에서 처리한 결과를 다른 서버들과도 동기화하여 데이터의 안정성을 보장해줍니다. 셋째, 운영(active) 서버가 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영서버로 바꿔서 서비스가 중지 없이 제공되게 해줍니다. 넷째, 분산 환경을 구성하는 서버들의 환경설정을 통합적으로 관리해줍니다. (공식 사이트: http://zookeeper.apache.org/)
2. Ooozie
하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템입니다. 자바 서블릿 컨테이너에서 실행되는 자바 웹 애플리케이션 서버이며, MapReduce 작업이나 Pig 작업 같은 특화된 액션들로 구성된 워크 플로우를 제어합니다. 참고로 2011년 7월에 아파치 인큐베이션에 포함됐습니다. (공식 사이트: http://incubator.apache.org/oozie)
3. HBase
HDFS 기반의 칼럼 기반 데이터 베이스입니다. 구글의 BigTable 논문을 기반으로 개발됐습니다. 실시간 랜덤 조회 및 업데이트가 가능하며, 각 각의 프로세스들은 개인의 데이터를 비동기적으로 업데이트할 수 있습니다. 단, MapReduce는 일괄 처리 방식으로 수행됩니다. 트위터, 야후, 어도비 같은 해외 업체들이 HBase를 사용하고 있으며, 국내에서는 얼마 전 NHN이 모바일 메신저인 라인에 HBase를 적용한 시스템 아키텍처를 발표하였습니다. (공식 사이트: http://hbase.apache.org)
4. Pig
야후에서 개발되었으나 현재는 아파치 프로젝트에 속해있습니다. 복잡한 MapReduce 프로그래밍을 대체할 Pig Latin이라는 자체 언어를 제공합니다. MapReduce API를 매우 단순화시키고, SQL과 유사한 형태로 설계됐습니다. SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하는 것이 어려운 편입니다. (공식 사이트: http://pig.apache.org)
5. Hive
하둡 기반의 데이터웨어하우징용 솔루션입니다. 페이스북에서 개발됐으며, 오픈 소스로 공개되며 주목을 받은 기술입니다. SQL과 매우 유사한 HiveQL이라는 쿼리를 제공합니다. 그래서 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 MapReduce 잡으로 변환되어 실행됩니다. (공식 사이트: http://hive.apache.org)
6. Mahout
하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈 소스입니다. 현재 분류 (classification), 클러스터링 (clustering), 추천 및 협업 필터링 (Recommenders/collaborative filtering), 패턴 마이닝 (Pattern Mining), 회귀 분석 (Regression), 차원 리덕션 (Dimension reduction), 진화 알고리즘 (Evolutionary Algorithms) 등 중요한 알고리즘을 지원하고 있습니다. Mahout을 그대로 사용할 수도 있지만, 자신의 비즈니스 환경에 맞게 최적화해서 사용하는 경우가 많습니다. (공식 사이트: http://mahout.apache.org)
7. HCatalog
하둡으로 생성한 데이터를 위한 테이블 및 스토리지 관리 서비스입니다. HCatalog의 가장 큰 장점은 하둡 에코 시스템들간의 상호 운용성 향상입니다. 예를 들어 Hive에서 생성한 테이블이나 데이터 모델을 Pig나 MapReduce에서 손쉽게 이용할 수가 있는 것입니다. 물론 그 전에도 에코 시스템간에 데이터 모델 공유가 불가능한 것은 아니었지만, 상당한 백엔드 작업이 필요했습니다. (공식 사이트: http://incubator.apache.org/hcatalog)
8. Avro
RPC(Remote Procedure Call)과 데이터 직렬화를 지원하는 프레임워크입니다. JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포맷으로 데이터를 직렬화합니다. (공식 사이트: http://avro.apache.org)
9. Chukwa
분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장시키는 플랫폼입니다. 분산된 각 서버에서 에이전트(agent)를 실행하고, 콜랙터(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장합니다. 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 MapReduce로 처리합니다. 야후에서 개발됐으며, 현재는 아파치 인큐베이션에 포함되어 있습니다. (공식 사이트: http://incubator.apache.org/chukwa)
10. Flume
Chukwa 처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜랙터로 구성됩니다. 차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서, 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할 지를 동적으로 변경할 수가 있습니다. 클라우드데라에서 개발됐으며, 현재는 아파치 인큐베이션에 포함되어 있습니다. (공식 사이트: http://incubator.apache.org/projects/flume.html)
11. Scribe
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식입니다. 최종 데이터는 HDFS외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원합니다. HDFS에 저장하기 위해서는 JNI(Java Native Interface)를 이용해야 합니다. (공식 사이트: https://github.com/facebook/scribe)
12. Sqoop
대용량 데이터 전송 솔루션이며, 올해 4월 아파치의 top-level 프로젝트가 됐습니다. Sqoop은 HDFS, RDBMS, DW, NoSQL등 다양한 저장소에 대용량 데이터를 신속하게 전송할 수 있는 방법을 제공합니다. Oracle, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, PostgresSQL과 같은 오픈소스 RDBMS등을 지원합니다. (공식 사이트: http://sqoop.apache.org)
13. Hiho
Sqoop과 같은 대용량 데이터 전송 솔루션이며, 현재 github에서 공개되어 있습니다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원합니다. 현재는 Oracle과 MySQL의 데이터 전송만 지원합니다. (공식 사이트: https://github.com/sonalgoyal/hiho)
출처 : https://david2kim.tistory.com/162
코디네이터
- Zookeeper(http://zookeeper.apache.org)
분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템으로, 크게 다음과 같은 네 가지 역할을 수행합니다. 첫째, 하나의 서버에만 서비스가 집중되지 않게 서비스를 알맞게 분산해 동시에 처리하게 해줍니다. 둘째, 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해서 데이터의 안정성을 보장합니다. 셋째, 운영(active) 서버에 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영 서버로 바꿔서 서비스가 중지 없이 제공되게 합니다. 넷째, 분산 환경을 구성하는 서버의 환경설정을 통합적으로 관리합니다.
리소스 관리
- YARN(http://hadoop.apache.org)
얀(YARN)은 데이터 처리 작업을 실행하기 위한 클러스터 자원(CPU, 메모리, 디스크등)과 스케쥴링을 위한 프레임워크입니다. 기존 하둡의 데이터 처리 프레임워크인 맵리듀스의 단점을 극복하기 위해서 시작된 프로젝트이며, 하둡2.0부터 이용이 가능합니다. 맵리듀스, 하이브, 임팔라, 타조, 스파크 등 다양한 애플리케이션들은 얀에서 리소스를 할당받아서, 작업을 실행하게 됩니다. 얀에 대한 자세한 설명은 http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/index.html을 참고하시기 바랍니다.
- Mesos(http://mesos.apache.org)
메소스(Mesos)는 클라우드 인프라스트럭처 및 컴퓨팅 엔진의 다양한 자원(CPU, 메모리, 디스크)을 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트입니다. 메소스는 2009년 버클리 대학에서 Nexus 라는 이름으로 시작된 프로젝트이며, 2011년 메소스라는 이름으로 변경됐으며, 현재는 아파치 탑레벨 프로젝트로 진행중이며, 페이스북, 에어비엔비, 트위터, 이베이 등 다양한 글로벌 기업들이 메소스로 클러스터 자원을 관리하고 있습니다. 메소스는 클러스터링 환경에서 동적으로 자원을 할당하고 격리해주는 매커니즘을 제공하며, 이를 통해 분산 환경에서 작업 실행을 최적화시킬 수 있습니다. 1만대 이상의 노드에도 대응이 가능하며, 웹 기반의 UI, 자바, C++, 파이썬 API를 제공합니다. 하둡, 스파크(Spark), 스톰(Storm), 엘라스틱 서치(Elastic Search), 카산드라(Cassandra), 젠킨스(Jenkins) 등 다양한 애플리케이션을 메소스에서 실행할 수 있습니다.
데이터 저장
- HBase(http://hbase.apache.org)
H베이스(HBase)는 HDFS 기반의 칼럼 기반 데이터베이스입니다. 구글의 빅테이블(BigTable) 논문을 기반으로 개발됐습니다. 실시간 랜덤 조회 및 업데이트가 가능하며, 각 프로세스는 개인의 데이터를 비동기적으로 업데이트할 수 있습니다. 단, 맵리듀스는 일괄 처리 방식으로 수행됩니다. 트위터, 야후!, 어도비 같은 해외 업체에서 사용하고 있으며, 국내에서는 2012년 네이버가 모바일 메신저인 라인에 HBase를 적용한 시스템 아키텍처를 발표했습니다.
- Kudu(http://getkudu.io)
쿠두(Kudu)는 컬럼 기반의 스토리지로서, 특정 컬럼에 대한 데이터 읽기를 고속화할 수 있습니다. 물론 기존에도 HDFS에서도 파케이(Parquet), RC, ORC와 같은 파일 포맷을 사용하면 컬럼 기반으로 데이터를 저장할 수 있지만, HDFS 자체가 온라인 데이터 처리에 적합하지 않다는 약점이 있었습니다. 그리고 HDFS 기반으로 온라인 처리가 가능한 H베이스의 경우, 데이터 분석 처리가 느리다는 단점이 있었습니다. 쿠두는 이러한 문제점들을 보완하여 개발한 컬럼 기반 스토리지이며, 데이터의 발생부터 분석까지의 시간을 단축시킬 수 있습니다. 클라우데라에서 시작된 프로젝트이며, 2015년말 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 수집
- Chukwa(http://chukwa.apache.org)
척와(Chuckwa)는 분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장하는 플랫폼입니다. 분산된 각 서버에서 에이전트(agent)를 실행하고, 콜렉터(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장합니다. 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 맵리듀스로 처리합니다. 야후!에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Flume(http://flume.apache.org)
플럼(Flume)은 척와처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜랙터로 구성됩니다. 차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할지를 동적으로 변경할 수 있습니다. 클라우데라에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Scribe(https://github.com/facebook/scribe)
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식입니다. 최종 데이터는 HDFS 외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원합니다. HDFS에 저장하려면 JNI(Java Native Interface)를 이용해야 합니다.
- Sqoop(http://sqoop.apache.org)
스쿱(Sqoop)은 대용량 데이터 전송 솔루션이며, 2012년 4월에 아파치의 최상위 프로젝트로 승격됐습니다. Sqoop은 HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송하는 방법을 제공합니다. 오라클, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, 포스트그레스큐엘(PostgreSQL)과 같은 오픈소스 RDBMS 등을 지원합니다.
- Hiho(https://github.com/sonalgoyal/hiho)
스쿱과 같은 대용량 데이터 전송 솔루션이며, 현재 깃헙(GitHub)에 공개돼 있습니다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원합니다. 현재는 오라클과 MySQL의 데이터 전송만 지원합니다.
- Kafka(http://kafka.apache.org)
카프카(Kafka)는 데이터 스트림을 실시간으로 관리하기 위한 분산 메세징 시스템입니다. 2011년 링크드인에서 자사의 대용량 이벤트처리를 위해 개발됐으며, 2012년 아파치 탑레벨 프로젝트가 됐습니다. 발행(publish)-구독(subscribe) 모델로 구성되어 있으며, 데이터 손실을 막기 위하여 디스크에 데이터를 저장합니다. 파티셔닝을 지원하기 때문에 다수의 카프카 서버에서 메세지를 분산 처리할 수 있으며, 시스템 안정성을 위하여 로드밸런싱과 내고장성(Fault Tolerant)를 보장합니다. 다수의 글로벌 기업들이 카프카를 사용하고 있으며, 그중 링크드인은 하루에 1조1천억건 이상의 메세지를 카프카에서 처리하고 있습니다.
데이터 처리
- Pig(http://pig.apache.org)
피그(Pig)는 야후에서 개발됐으나 현재는 아파치 프로젝트에 속한 프로젝트로서, 복잡한 맵리듀스 프로그래밍을 대체할 피그 라틴(Pig Latin)이라는 자체 언어를 제공합니다. 맵리듀스 API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계됐습니다. SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하기가 어려운 편입니다.
- Mahout(http://mahout.apache.org)
머하웃(Mahout)은 하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스 프로젝트입니다. 현재 분류(classification), 클러스터링(clustering), 추천 및 협업 필터링(Recommenders/collaborative filtering), 패턴 마이닝(Pattern Mining), 회귀 분석(Regression), 차원 리덕션(Dimension reduction), 진화 알고리즘(Evolutionary Algorithms) 등 중요 알고리즘을 지원합니다. Mahout을 그대로 사용할 수도 있지만 각 비즈니스 환경에 맞게 최적화해서 사용하는 경우가 많습니다.
- Spark(http://spark.apache.org)
스파크(Spark)는 인메모리 기반의 범용 데이터 처리 플랫폼입니다. 배치 처리, 머신러닝, SQL 질의 처리, 스트리밍 데이터 처리, 그래프 라이브러리 처리와 같은 다양한 작업을 수용할 수 있도록 설계되어 있습니다. 2009년 버클리 대학의 AMPLab에서 시작됐으며, 2013년 아파치 재단의 인큐베이션 프로젝트로 채택된 후, 2014년에 탑레벨 프로젝트로 승격됐습니다. 현재 가장 빠르게 성장하고 있는 오픈소스 프로젝트 중의 하나이며, 사용자와 공헌자가 급격하게 증가하고 있습니다.
- Impala(http://impala.io)
임팔라(Impala)는 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진입니다. 맵리듀스를 사용하지 않고, C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여줍니다. 임팔라는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있습니다. 2015년말 아파치 재단의 인큐베이션 프로젝트로 채택됐습니다.
- Presto(https://prestodb.io)
프레스토(Presto)는 페이스북이 개발한 대화형 질의를 처리하기 위한 분산 쿼리 엔진입니다. 메모리 기반으로 데이터를 처리하며, 다양한 데이터 저장소에 저장된 데이터를 SQL로 처리할 수 있습니다. 특정 질의 경우 하이브 대비 10배 정도 빠른 성능을 보여주며, 현재 오픈소스로 개발이 진행되고 있습니다.
- Hive(http://hive.apache.org)
하이브(Hive)는 하둡 기반의 데이터웨어하우징용 솔루션입니다. 페이스북에서 개발했으며, 오픈소스로 공개되며 주목받은 기술입니다. SQL과 매우 유사한 HiveQL이라는 쿼리 언어를 제공합니다. 그래서 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행됩니다.
- Tajo(http://tajo.apache.org)
타조(Tajo)는 고려대학교 박사 과정 학생들이 주도해서 개발한 하둡 기반의 데이터 웨어하우스 시스템입니다. 2013년 아파치 재단의 인큐베이션 프로젝트로 선정됐으며, 2014년 4월 최상위 프로젝트로 승격됐습니다. 맵리듀스 엔진이 아닌 자체 분산 처리 엔진을 사용하며, HiveQL을 사용하는 다른 시스템들과는 다르게 표준 SQL을 지원하는 것이 특징입니다. HDFS, AWS S3, H베이스, DBMS 등에 저장된 데이터 표준 SQL로 조회할 수 있고, 이기종 저장소간의 데이터 조인 처리도 가능합니다. 질의 유형에 따라서 하이브나 스파크보다 1.5 ~ 10배 빠른 성능을 보여줍니다.
워크플로우 관리
- Oozie(http://oozie.apache.org)
우지(Oozie)는 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템입니다. 자바 서블릿 컨테이너에서 실행되는 자바 웹 애플리케이션 서버이며, 맵리듀스 작업이나 피그 작업 같은 특화된 액션으로 구성된 워크플로우를 제어합니다.
데이터 시각화
- Zeppelin (https://zeppelin.incubator.apache.org)
제플린(Zeppelin)은 빅데이터 분석가를 위한 웹 기반의 분석 도구이며, 분석결과를 즉시 표, 그래프로 제공하는 시각화까지 지원합니다. 아이파이썬(iPython)의 노트북(Notebook)과 유사한 노트북 기능을 제공하며, 분석가는 이를 통해 손쉽게 데이터를 추출, 정제, 분석, 공유를 할 수 있습니다. 또한 스파크, 하이브, 타조, 플링크(Flink), 엘라스틱 서치, 카산드라, DBMS 등 다양한 분석 플랫폼과 연동이 가능합니다. 2013년 엔에프랩의 내부 프로젝트로 시작됐으며, 2014년 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 직렬화
- Avro(http://avro.apache.org)
RPC(Remote Procedure Call)와 데이터 직렬화를 지원하는 프레임워크입니다. JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포맷으로 데이터를 직렬화합니다. 경쟁 솔루션으로는 아파치 쓰리프트(Thrift), 구글 프로토콜 버퍼(Protocol Buffer) 등이 있습니다.
- Thrift(http://thrift.apache.org)
쓰리프트(Thrift)는 서로 다른 언어로 개발된 모듈들의 통합을 지원하는 RPC 프레임워크입니다. 예를 들어 서비스 모듈은 자바로 개발하고, 서버 모듈은 C++로 개발되었을때, 쓰리프트로 쉽게 두 모듈의 통신 코드를 생성할 수 있습니다. 쓰리프트는 개발자가 데이터 타입과 서비스 인터페이스를 선언하면, RPC 형태의 클라이언트와 서버 코드를 자동으로 생성합니다. 자바, C++, C#, Perl, PHP, 파이썬, 델파이, Erlang, Go, Node.js 등과 같이 다양한 언어를 지원합니다.